
Langage SQL
Le NULL en SQL
Les subtilités d’un langage puissant de requêtes
Décrit le comportement de la valeur NULL en SQL
Le comportement de la valeur NULL en SQL peut être déroutant lorsque l’on n’en connaît pas la logique et si l’on n’a pas compris que NULL n’était pas une valeur comme les autres mais spécifiait au contraire une absence de valeur.
1. Principe
Lorsque l’on définie la structure d’une table dans une base de donnée relationnelle, on peut spécifier pour chaque champ si l’on accepte ou pas de renseigner sa valeur. Cela permet de valider un enregistrement sans pour autant renseigner la totalité de ses champs. Cela peut être utile dans de nombreux cas. Si vous créez une table de personnels, vous pouvez avoir un champ date pour spécifier la date de fin de contrat de ce personnel. Il est évident que si vous créez une fiche lors de l’embauche de ce dernier, il y a peu de chance que vous connaissiez sa date de départ s’il s’agit d’un CDI alors que vous avez besoin d’enregistrer sa fiche. Vous devrez donc permettre que ce champ ne soit pas rempli lors de la saisie. Dans ce cas il aura une valeur particulière nommé : NULL. Comme dans la plupart des SGBD , lorsque vous ne spécifiez rien lors de la définition d’un champ, c’est le NULL autorisé qui est la valeur par défaut. Il faut donc connaître les conséquences de cette valeur (ou plutôt absence de valeur) lors de la définition de requêtes si l’on ne veut pas obtenir des résultat avec des lignes manquantes sans comprendre pourquoi.
2. Un petit exemple avec une clause WHERE
Nous allons prendre comme exemple une table contenant les données suivantes :
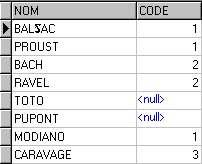
Cette table pourrait représenter des noms d’artistes suivi d’un code renseignant s’il s’agit d’écrivains (code 1), de musiciens (code 2) ou de peintres (code 3). Nous n’avons pas renseigné le champ code pour 2 personnes, les champs ont donc la valeur NULL. Nous constatons que nous avons 8 enregistrements.
Si nous désirons avoir tous les peintres de la liste il nous suffit de définir la requête suivante :
- SELECT * FROM test WHERE code=3
Un seul nom répond à ce critère dans notre table :
![]()
Si maintenant, nous désirons récupérer tous les artistes qui ne sont pas peintres (code différent de 3) nous devrions récupérer tous les autres enregistrements, c’est à dire 7 enregistrement (8 - 1 = 7) en définissant la requête suivante :
- SELECT * FROM test WHERE code <> 3
Nous obtenons le résultat suivant :
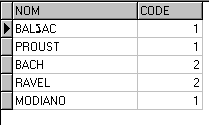
Nous aurions pu nous attendre à retrouver toutes les lignes sauf celle contenant la valeur 3 ("CARAVAGE") alors que "TOTO" et "DUPONT" qui n’ont pas la valeur 3 n’ont pas été sélectionnés. Cela est due au fait que NULL n’est pas une valeur normale puisque cela indique l’absence de donnée dans le champ.
Ce qu’il faut savoir, c’est que lorsqu’un test est effectué sur un champ contenant NULL, le résultat ne correspond ni à vrai (TRUE) ni à faux (FALSE) mais une valeur particulière : UNKNOWN (inconnu). Dans notre exemple notre clause WHERE donne :
| Test | résultat | conséquence |
|---|---|---|
| WHERE 2 <> 3 | TRUE | la ligne est prise |
| WHERE 3 <> 3 | FALSE | la ligne n’est pas prise |
| WHERE NULL <> 3 | UNKNOWN | la ligne n’est pas prise puisque UNKNOWN est différent de TRUE |
Si nous désirons récupérer la liste de toutes les personnes pour lesquels nous n’avons pas spécifié qu’elles étaient peintres, nous devons modifier notre requête comme suit :
- SELECT * FROM test WHERE ( code <> 3 ) OR ( code IS NULL )

3. Le cas d’une jointure
Imaginons maintenant les 2 tables suivantes ne contenant qu’un seul champ nommé CODE :
T_TABLE_UN
| CODE |
|---|
| 1 |
| 2 |
T_TABLE_DEUX
| CODE |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
Si nous écrivons maintenant la requête suivante :
- SELECT CODE FROM T_TABLE_DEUX WHERE CODE NOT IN ( SELECT CODE_UN FROM T_TABLE_UN )
Cela nous permet de sélectionner tous les enregistrements de la seconde table pour lesquels il n’y a pas de correspondance dans la première table.
Nous obtenons bien le résultat suivant :
| CODE |
|---|
| 3 |
| 4 |
| 5 |
Maintenant, ajoutons un nouvel enregistrement avec la valeur NULL dans la première table :
| CODE |
|---|
| 1 |
| 2 |
| NULL |
Si nous ré-exécutons notre requête SELECT et bien nous nous retrouvons avec un résultat vide, ce qui peut surprendre au départ.
En fait, ce résultat est très logique si l’on comprend comment le SGBD exécute notre instruction.
Si l’on prend notre requête
- SELECT CODE FROM T_TABLE_DEUX WHERE CODE NOT IN ( SELECT CODE_UN FROM T_TABLE_UN )
Dans le cas de notre exemple, c’est comme si nous avions écrit :
- SELECT CODE FROM T_TABLE_DEUX WHERE ( ( CODE <> 1 ) AND ( CODE <> 2 ) AND ( CODE <> NULL ) )
Ce qui donne par exemple pour le 3° enregistrement de la seconde table dont le champ CODE est 3 :
WHERE ( TRUE AND TRUE AND UNKNOWN )Puisque le 3° test ne renvoi pas TRUE, le résultat général ne sera pas TRUE non plus mais UNKNOWN. On voit donc que quelque soit la valeur de CODE de la seconde table, le résultat du test ne renvoyant pas TRUE, l’enregistrement n’est jamais accepté dans le résultat.
De plus ce résultat est parfaitement logique puisque lorsque nous avons écrit cette requête c’était bien dans le but de sélectionner tous les enregistrements de la seconde table pour lesquels il n’y avait pas de correspondance dans la première. Alors comment répondre à cette question si nous ne connaissons pas exactement le contenu de cette première table. Rappelez-vous que lorsque nous avons ajouté un enregistrement avec la valeur NULL ce n’était pas pour dire que CODE n’était pas 1, n’était pas 2, etc mais que nous ne connaissions pas sa valeur au moment ou nous avons créé l’enregistrement.
4. La logique de NULL
On voit que lorsque l’on effectue des comparaisons avec la valeur NULL nous obtenons une valeur qui n’est ni TRUE, ni FALSE mais UNKNOWN. L’intérêt de ce comportement est de permettre de tester à l’aide d’une requête si l’on a des champs non renseignés. On doit donc pouvoir différentier un 0 d’une absence de valeur (NULL) dans un champ numérique par exemple. Il est logique qu’un test sur un champ ayant la valeur NULL, donc inconnue, ne renvoie ni vrai ni faux.
5. Fonctions de gestion de la valeur NULL
Pour tester si un champ est NULL ou pas vous devrez utiliser le prédicat suivant :
IS [NOT] NULLLa plupart des SGBD proposent également des fonctions permettant de manipuler la valeur NULL. En voici quelques unes :
| Fonction | Description |
|---|---|
| NULLIF( V1, V2 ) | Si V1 = V2 renvoi NULL sinon renvoi V1 |
| IFNULL( V1, V2 ) | Si V1 est NULL, retourne V2 sinon V1 |
| COALESCE( V1, V2,...) | Parcoure chaque élément de gauche à droite et renvoi le premier non NULL. La fonction renvoie NULL si l’ensemble des éléments sont NULL. |
D’autre part, pour être sur de se retrouver avec des tests renvoyant TRUE ou FALSE même lorsqu’il risque d’avoir des valeur NULL, SQL propose le prédicat suivant :
<condition de recherche> IS [NOT] TRUE | FALSE | UNKNOWNPar exemple, on pourrait modifier la requête précédente en l’écrivant comme cela :
- SELECT CODE FROM T_TABLE_DEUX WHERE ( CODE IN ( SELECT CODE FROM T_TABLE_UN ) IS NOT TRUE );
qui nous donnera bien le résultat suivant :
| CODE |
|---|
| 3 |
| 4 |
| 5 |
6. Clé primaire et valeur NULL
En principe, le SGBDR vous interdira la valeur NULL dans un champ clé ce qui serait sinon contradictoire puisque le rôle d’une clé est de pouvoir identifier un enregistrement.
7. Quelques règles
- Une valeur NULL ne peut être insérée dans une colonne définie comme NOT NULL.
- Les valeur NULL ne sont pas égales entre elles d’où l’utilité des expressions de type IS [NOT] NULL dans les clauses WHERE.
- Une colonne contenant une valeur NULL est ignorée dans le calcul de valeurs agrégée comme AVG, SUM, COUNT, MAX, …
- Dans un ORDER BY, la norme ne précise pas la règle de classement pour les NULL.
- DISTINCT ORDER BY et GROUP BY considèrent que les valeurs NULL ne peuvent être distinguées entre elles et sont regroupées.
7. Conclusion
Les spécialistes du SQL peuvent discuter longtemps sur ce que veut dire NULL en bases de données. Par exemple imaginez que vous ayez une table de personnels avec un champ couleur de cheveux. Si ce champ est NULL est-ce que vous en concluez que c’est parce que la couleur de ces cheveux était inconnue au moment de la création de l’enregistrement ou parce que ce personnel est chauve et que donc cette information n’est pas applicable dans ce cas ?
Comme la valeur NULL peut être source de pièges dans l’utilisation des requêtes, il est conseillé, lors de la définition d’un champ, de n’autoriser la valeur NULL que lorsque cela est justifié, c’est à dire lorsque la valeur à renseigner est susceptible de ne pas être connue lors de la saisie d’un nouvel enregistrement mais qu’elle pourra l’être plus tard. Et pour en revenir au cas concernant la couleurs de cheveux on pourrait, par exemple, ajouter un champ indiquant si la personne est chauve ou pas, ce qui permettrait de préciser le sens de NULL dans le champ couleur de cheveux.
Article n° 9
Crée par: chris
Créé le: 1er janvier 2012
Modifié le: 1er novembre 2019
Nombre de visites: 184
Popularité: 13 %
Popularité absolue: 1
Langage SQL
Mots clés de cet article
- SQL12

2003-2024 LePpf
Plan du site
| Se connecter |
RSS 2.0 |
Sur YouTube
Visiteurs connectés : 4
Nombre moyen de visites quotidiennes sur le site: 197